Posted: 11/30/2017
Znajomość dokładnego sposobu działania tak elementarnej funkcji jak sortowanie liczb wydaje się w obecnych czasach zbędna. Większość z najpopularniejszych aktualnie języków programowania ma ją domyślnie zaimplementowaną i dla najpowszechniej występujących zbiorów danych sprawują się bez zarzutu. Jednak czy to na pewno dobre rozwiązanie? Co zrobić, gdy mamy do czynienia z niestandardowym lub po prostu bardzo dużym zbiorem danych?
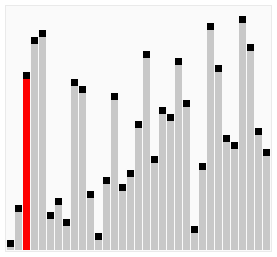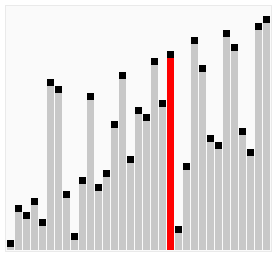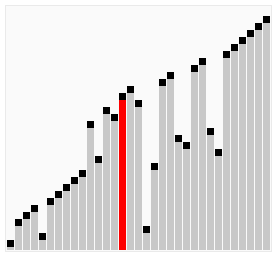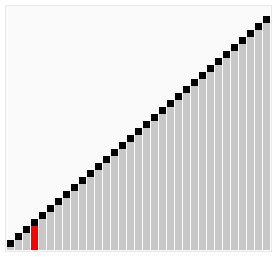
Odpowiedzią na postawione pytania jest praktyka. Znajomość działania “od kuchni” najpopularniejszych metod sortowania może się okazać bardzo przydatna do zoptymalizowania naszego algorytmu. Każda z obecnie używanych metod posiada swoje specyficzne zalety i wady. Dla pewnych zbiorów danych przewaga jednego algorytmu nad drugim może się uwidaczniać (grafika poniżej). Ponadto, rozwiązywanie na nowo już rozwiązanych problemów (zobacz: kata) jest świetnym sposobem na szlifowanie swoich programistycznych umiejętności. Z tego powodu, w dzisiejszym poście postaram się pokazać przykładowy sposób, w jaki można posortować tablicę losowych liczb.
Knowledge of the exact way of working of such a basic function as the sorting of numbers seems unnecessary these days. Most of the currently popular programming languages have it implemented by default and perfectly well for the most common data sets. However, is it really a good solution? What to do when dealing with a custom or simply very large sets of data?
The answer to the questions posed is practice. Knowledge how it works from inside can be very useful to optimize our algorithm. Each of the currently used methods has its own specific pros and cons. For some data sets, the advantage of one algorithm over another may expose (gif below). What’s more, resolving already solved problem (check: kata) is a great way to improve your programming skills. For this reason, in today’s post I will try to show you an example of how you can sort an array of random numbers.
 źródło _source sorting-algorithms.com
źródło _source sorting-algorithms.com
Do posortowania tablicy liczb wykorzystamy metodę sortowania bąbelkowego (ang. Bubble sort). Polega ona na przesuwaniu największej (lub najmniejszej, jeśli sortujemy malejąco) liczby na koniec sortowanego zbioru. “Przesuwanie” odbywa się poprzez porównywanie ze sobą kolejnych liczb w tablicy. Jeśli liczba o niższym indeksie w tablicy ma większą wartość niż liczba występująca po niej, są zamieniane miejscami.
Po każdej iteracji ostatnia liczba jest “odcinana” - została posortowana i nie musi być już porównywana z resztą liczb w zbiorze, gdyż posiada skrajną wartość. Algorytm porównywania liczb jest powtarzany n - 1 razy, gdzie n to liczba elementów zbioru.
To sort the array we use the Bubble sort method. It consists in moving the largest (or the smallest if we sort descending) the number at the end of the sorted set. “Moving” is done by comparing subsequent numbers in the table with each other. If the number with the lower index in the array has a higher value than the number after it, they are swapped.
After each iteration, the last number is “cutted of” - it has been sorted and doesn’t need to be compared with the rest of the numbers in the set, because it has maximum (or minimum) value. The number comparison algorithm is repeated n - 1 times, where n is the size of the set.
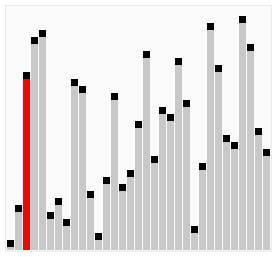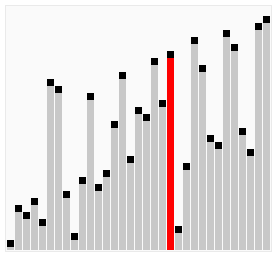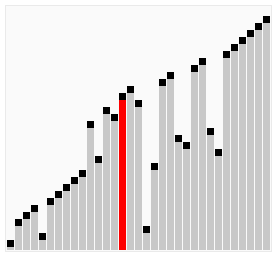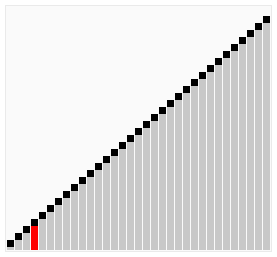 źródło source wikipedia.org
źródło source wikipedia.org
{kind=link}
Przygotowanie zbioru danych / Preparation of the data set
Przed rozpoczęciem implementowania algorytmu Bubble sort musimy podjąć pewne założenia odnośnie sortowanego zbioru. Dla uproszczenia przyjmijmy, że rozmiar zbioru będzie pewną stałą (SIZE). Liczby składające się na zbiór będą natomiast losowane przy każdym uruchomieniu programu, jednak ze stałego zakresu ( (0; RANGE> ). Implementację algorytmu zaczynamy więc od zadeklarowania dwóch stałych globalnych.
Before we start implementing the Bubble sort algorithm, we have to make some assumptions about the sorted set of data. To simplify, assume that the size of the set will be a constant (SIZE). The numbers that make up the set will be randomly selected every time the program is launched, but from a fixed range ( (0; RANGE> ). So, we start the implementation by declaring two global constants.
#include <stdio.h>
const int SIZE = 10; // constant int for size of array
const int RANGE = 20; // constant int for range of random numbers in array
int main()
{
return 0;
}Kolejnym krokiem jest przygotowanie zbioru do posortowania. Tworzymy tablicę liczb całkowitych o rozmiarze zadeklarowanym w stałej SIZE. Następnie w pętli wypełniamy ją losowymi elementami.
The next step is to prepare the collection for sorting. We create an array of integers of the size declared in constant SIZE_. Then we fill it with random numbers in loop._
#include <stdio.h>
#include <time.h>
const int SIZE = 10;
const int RANGE = 20;
int main()
{
int tabToSort[SIZE]; // array declaration
srand(time(0)); // 1
for(int i = 0; i < SIZE; i++)
{
tabToSort[i] = rand() % RANGE + 1; // (2)
printf("%d ", tabToSort[i]); // print array element
}
return 0;
}W języku C przed rozpoczęciem losowania należy podać ziarno (ang. seed) w funkcji srand(), będące elementem początkowym służącym do generowania liczb pseudolosowych (1). Powszechnie stosowaną praktyką jest podawanie czasu zegara procesora w danym momencie (time() z biblioteki time.h).
Wyjaśnienia wymaga też sam sposób przypisywania liczb (2). rand() % RANGE powoduje wylosowanie liczb z zakresu od 0 do RANGE - 1, dlatego aby wyeliminować 0 z zakresu a jednocześnie dodać RANGE, przy przypisywaniu dodawana jest jedynka. Obecny output programu (w zależności od wylosowanych liczb) prezentuje się jak na screenie poniżej.
In C, before starting the draw, the seed should be given as the parameter in the srand() function. Seed is the initial element used to generate pseudo-random numbers (1). It’s a common practice to give the processor’s clock time _(_time() from the time.h library).
The way of assigning numbers (2) also needs to be explained. rand() % RANGE draws numbers from 0 to RANGE - 1_, so to eliminate 0 from the range and add_ RANGE_, a 1 is added when assigning._ The current output (depending on the numbers drawn) looks like on the screen below. 
Sortowanie bąbelkowe / Bubble sort
Po przygotowaniu zbioru danych pora na implementację właściwego algorytmu. Pierwszym krokiem jest opracowanie mechanizmu porównywania ze sobą składników zbioru w taki sposób, aby największa liczba znalazła się na końcu sortowanego zbioru. Można to wykonać przez iterowanie kolejnych elementów po indeksie w tablicy i porównywanie ich z kolejnym - o indeksie o 1 większym od aktualnie analizowanego.
After preparing the data set it’s the time to implement the proper algorithm. The first step is to develop a mechanism for comparing the elements of the set with each other in such way that the largest number will be at the end of the sorted set. This can be done be iterating subsequent elements by index in the array and comparing them with the next one - with index higher by 1 than currently analyzed.
for(int i = 0; i < SIZE - 1; i++) // iterate through elements in the array
{
if(tabToSort[i] > tabToSort[i+1]) // compare if element i is greater than elment i+1
{
int tmp = tabToSort[i]; // swapping elements
tabToSort[i] = tabToSort[i+1];
tabToSort[i+1] = tmp;
}
}Po wykonaniu pętli jak powyżej, największy element w zbiorze znalazł się na ostatniej pozycji. Naszym celem jest jednak posortowanie całej tablicy. Należy więc powtarzać algorytm tak, aby największa liczba znajdowała się po każdej iteracji na końcu zbioru (przed już wcześniej posortowanym). W każdej iteracji ubywa nam jeden element, co również należy uwzględnić w algorytmie, by nie wykonywać zbędnych porównań.
After making a loop as above, the largest element in the set is in the last position in the set. However, our goal is to sort the entire array. Therefore, the algorithm should be repeated so that the largest number was after each iteration at the end of the set (before the previously sorted one). In each iteration we lose one element, which should also be included in the algorithm, so as not to make unnecessary comparisons.
int n = SIZE; // (1)
do
{
for(int i = 0; i < SIZE - 1; i++)
{
if(tabToSort[i] > tabToSort[i+1])
{
int tmp = tabToSort[i];
tabToSort[i] = tabToSort[i+1];
tabToSort[i+1] = tmp;
}
}
n--; // (2)
} while (n > 1); // (3)Rozmiar tabeli zadeklarowaliśmy jako stałą, a więc nie można go zmieniać. Poza tym, będzie nam jeszcze potrzebny do końcowego wypisania posortowanej tablicy. Gdybyśmy zmienili go, utracilibyśmy informację o jej rozmiarze. Z tego powodu przypisujemy go do pomocniczej zmiennej n (1). Wcześniej napisany algorytm “obudowujemy” w kolejną pętlę (do while), która powtórzy mechanizm porównania dla zbiorów danych pomniejszanych kolejno o już posortowany element z ostatnim indeksem w tablicy (2). Pętla wykonuje się dopóty dopóki wszystkie elementy nie zostaną posortowane (3).
We declared the size of the array as a constant, so we cannot change it. Besides, we’ll still need it for the final listing of the sorted array. If we changed it, we would lose information about array size. For this reason, we assign it to variable n (1). The previously written algorithm is surrounded by another loop (do while), which will repeat the comparison mechanism for data sets reduced in turn by already sorted element (with the last index in array) (2). The loop is executed until all elements have been sorted (3).
Wyniki / Results
Pozostaje już tylko zaprezentować wynik na ekranie. Do wypisania posortowanej tablicy używamy podobnej pętli jak na początku, kiedy losowaliśmy do niej liczby.
Dobrze byłoby dodać również jakiś wskaźnik mówiący nam o tym, jak często jest wykonywana operacja dominująca (czyli porównania liczb) i czy jest to zależne od rodzaju danych wejściowych. Dodajemy więc zmienną numberOfComparisons, która będzie inkrementowana przed każdą operacją porównania liczb w sortowanej tablicy.
Po wykonaniu programu otrzymujemy wynik jak na screenie poniżej. Jakie wnioski na podstawie liczby porównań można wyciągnąć dla różnych zbiorów danych?
All that remains is to present the result on the screen. To print a sorted array we use a similar loop as at the beginning, when we drew numbers to it.
It would also be good to add some indicator telling us how often the dominant operation is performed (comparison of numbers) and whether it depends on the type of input data. So we add a variable numberOfComparisons_, which will be incremented before each comparison operation in sorted array._
After executing the program, we get the result as shown below. What conclusions can be drawn for different data sets based on the number of comparisons?

Kod gotowej aplikacji prezentuje się następująco:
The ready application code looks as follows:
#include <stdio.h>
#include <time.h>
const int SIZE = 10;
const int RANGE = 25;
int main()
{
int numberOfComparisons = 0;
int tabToSort[SIZE];
srand(time(0)); // 1
for(int i = 0; i < SIZE; i++)
{
tabToSort[i] = rand() % RANGE + 1; // (2)
printf("%d ", tabToSort[i]);
}
printf("\\n"); // new line
int n = SIZE;
do
{
for(int i = 0; i < n - 1; i++)
{
numberOfComparisons++; // comparisons counter
if(tabToSort[i] > tabToSort[i+1])
{
int tmp = tabToSort[i];
tabToSort[i] = tabToSort[i+1];
tabToSort[i+1] = tmp;
}
}
n--;
} while (n > 1);
for(int i = 0; i < SIZE; i++) // print result
{
printf("%d ", tabToSort[i]);
}
printf("\\n");
printf("Number of comparisons: %d", numberOfComparisons); // print number of comparisons
return 0;
}
Źródła / sources:
Kompilator online / Online compiler: